
The fast development of AI is having far-reaching effects on many different markets. Artificial intelligence is making a big splash in many fields, including computer vision. Starting in 2021 and continuing at a CAGR of 40.1%, the artificial intelligence (AI) market in computer vision is anticipated to reach $51.3 billion by 2026. A new dawn in the rapid automation of procedures and providing fresh insights by AI has revolutionized entire sectors. The crucial data annotation process is at the core of these revolutionary advances. In this blog we will look at two options for data annotation, in-house or outsourced.
In-house Data Annotation
Having an in-house text data labeling team has its advocates who argue that it’s better since it permits more stringent oversight, better security, and better intellectual property protection. The problem is that building AI models from scratch requires training data, which can be difficult, expensive, and time-consuming to generate.
The expense of employing, training, and supervising a staff of data labelers is simply too high for most companies. Renting larger offices and developing specialized software and equipment are two potential sources of rapidly rising costs. There will be a lot of staff turnover because data labeling is usually done on a project-by-project basis, which is another concern. This means beginning the recruiting and training process for each new project.

When so much is riding on data annotation, putting it on your engineers’ to-do lists is not a good idea. Classifying large datasets could take much time, or even worse; this vital step could be skipped. It could be challenging to label large datasets in time for a project’s due date or to react fast enough to requests to augment a machine learning training dataset with more data or labels, even when using in-house data annotation tools.
Outsourcing Data Annotation
The “best of both worlds” is what many companies discover when they team up with an outside, expert data-annotation company. Companies can cut costs without sacrificing quality by partnering with a long-standing, reliable company. Data labeling companies employ skilled annotators who are adaptable to client needs and well-versed in the most recent developments in annotation technology.
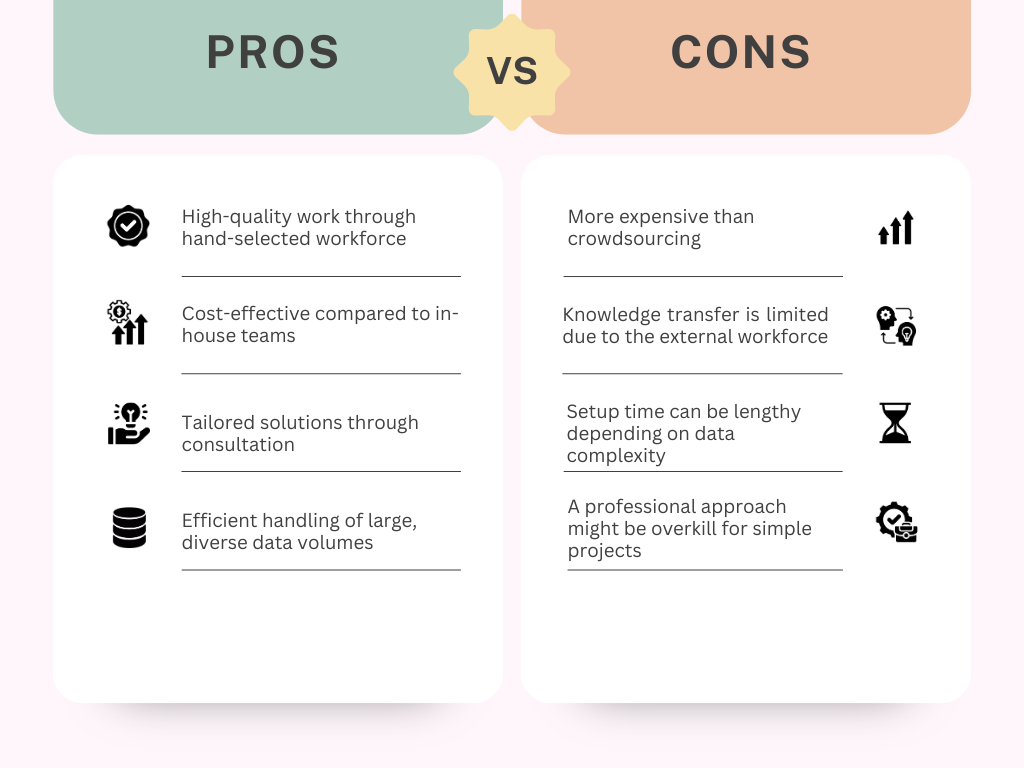
The ability to outsource can help you form a lasting relationship with your partner, which is especially useful if you intend to return with more data sets in the future. If you anticipate a seasonal increase and want a larger staff, your outsourcing partner can readily reallocate some of their employees to your account. It saves time and effort because no longer is it necessary to find, hire, train, and then fire personnel when business slows down.
When is outsourcing the right move for you?
These challenges can be addressed by outsourcing data annotation:
1. With outsourcing, you can fully concentrate on what counts.
An important but time-consuming step in training ML models is ensuring that data is appropriately labeled. Skilled data scientists cannot handle more complicated challenges since they are assigned to this monotonous labor. Hiring a third party to handle your data annotation can simplify your development process and free up your specialists to concentrate on creating strong ML models.
2. Quality and efficiency are guaranteed through outsourcing.
Timely completion and excellent standards are guaranteed when data annotation is outsourced. Expert teams that have worked with a wide variety of datasets will work on your project, using their knowledge to get the job done quickly and accurately.
3. With outsourcing, scaling is a breeze.
It could be difficult to manage the task of annotating large datasets. The total productivity of in-house teams might be negatively affected by workload fluctuations, which can cause delays and necessitate additional resources from other departments. No matter the size of your ML project, outsourcing makes it easy to scale up or down your text data labeling efforts.
5 Key Questions to Ask Before Outsourcing Data Annotation Work
- What kind of data is required?
You can’t train machine learning models with just any old data. You need images, videos, LiDAR (radar) scans, audio, and text. Use case, model complexity, training method, and input data diversity are among the variables that determine the necessary data type.
- Which annotation techniques will be employed?
Annotation methods like bounding boxes, semantic segmentation, and object recognition show how text data labeling tools and firms can differ in their capabilities and limits. Before deciding on a service provider, it is essential to understand their skills.
- What is the timeframe and budget for the data labeling project?
Evaluate the data labeling service’s ability to meet your deadlines in light of the project timeframe. Find out how well the supplier can increase resources while keeping quality and the project on schedule. Consider how much the data labeling service will cost and if it fits your budget. Find out whether the service meets your project’s requirements and is worth the expense.
- How will the project’s efficiency be assessed?
Find out your annotation project’s KPIs and ensure your service provider knows what they are. To ensure the efficiency of your findings and the effectiveness of your computer vision pipeline, it is vital to have clear requirements for data annotation.
- Does the annotation team have a dedicated platform?
Saving money and working faster are both possible with the correct tool. If the annotation team doesn’t have one, you might have to shell out more cash to get a scalable platform.
Conclusion
An average AI project requires the accurate labeling and annotation of thousands of data sets, which is labor-intensive. This spike in demand may cause your internal teams’ deliverables to take longer than expected, although the amount of data involved varies greatly depending on the project’s nature. You might have to ask other departments for aid to handle the increasing data volume, which could reduce productivity.
About SoftAge AI
SoftAge AI specializes in data management and AI-driven solutions, with a strong focus on linguistic diversity. Leveraging its extensive experience and innovative approaches, SoftAge AI is advancing digital transformation in India while preserving its rich cultural and linguistic heritage.


