Data labeling
SFT Datasets
RLHF
for Large Language Models
Build top-performing LLMs using highly-quality training data
-
Trusted by the world's top
- AI Labs &
- Entreprises





Overview
Data for Language Models
Get high-quality data for each stage of model building.
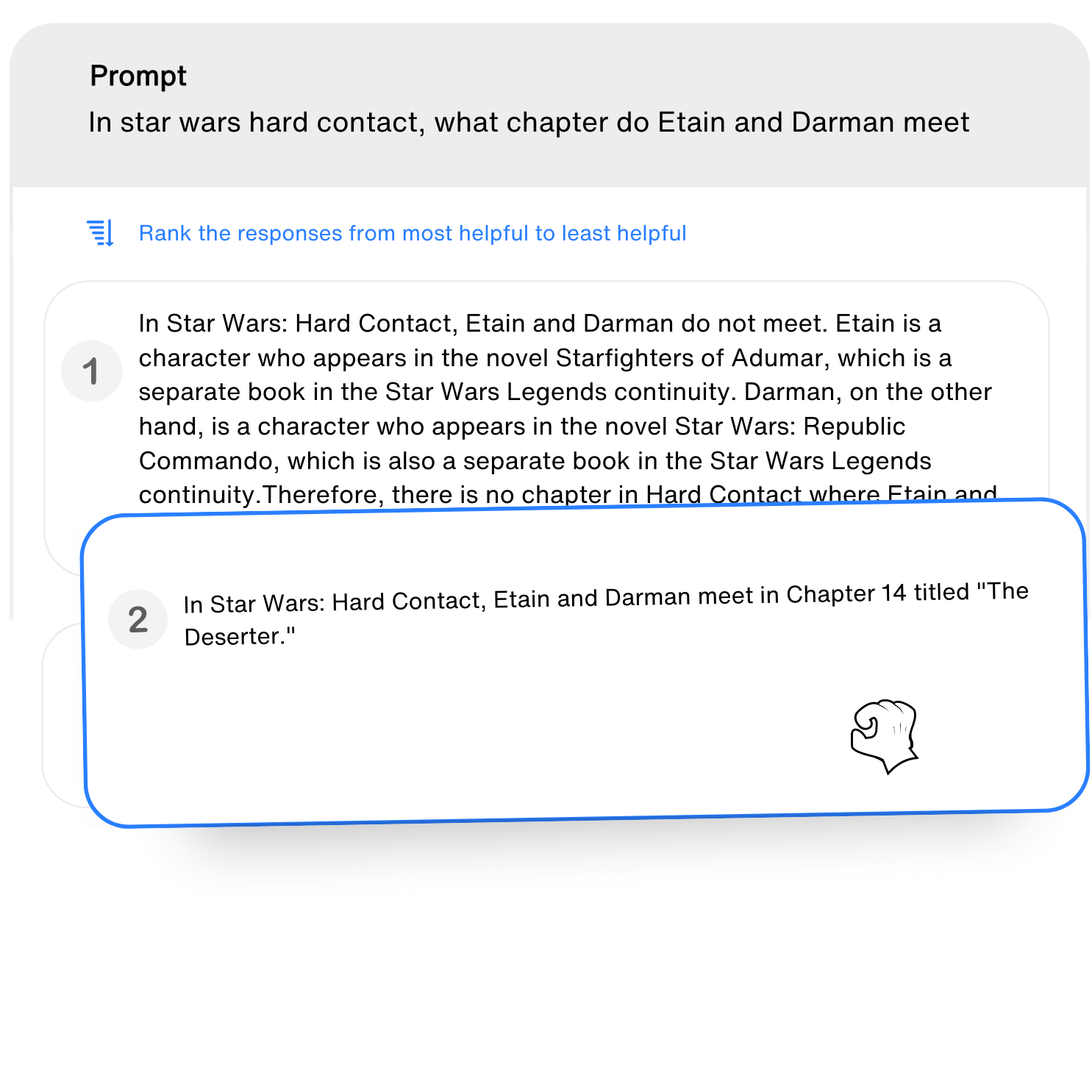
RLHF
Human preferences are applied to model outputs.
Response ranking for LLMs across various domains by employing subject matter expert raters, we generate high-quality feedback that enhances model performance.
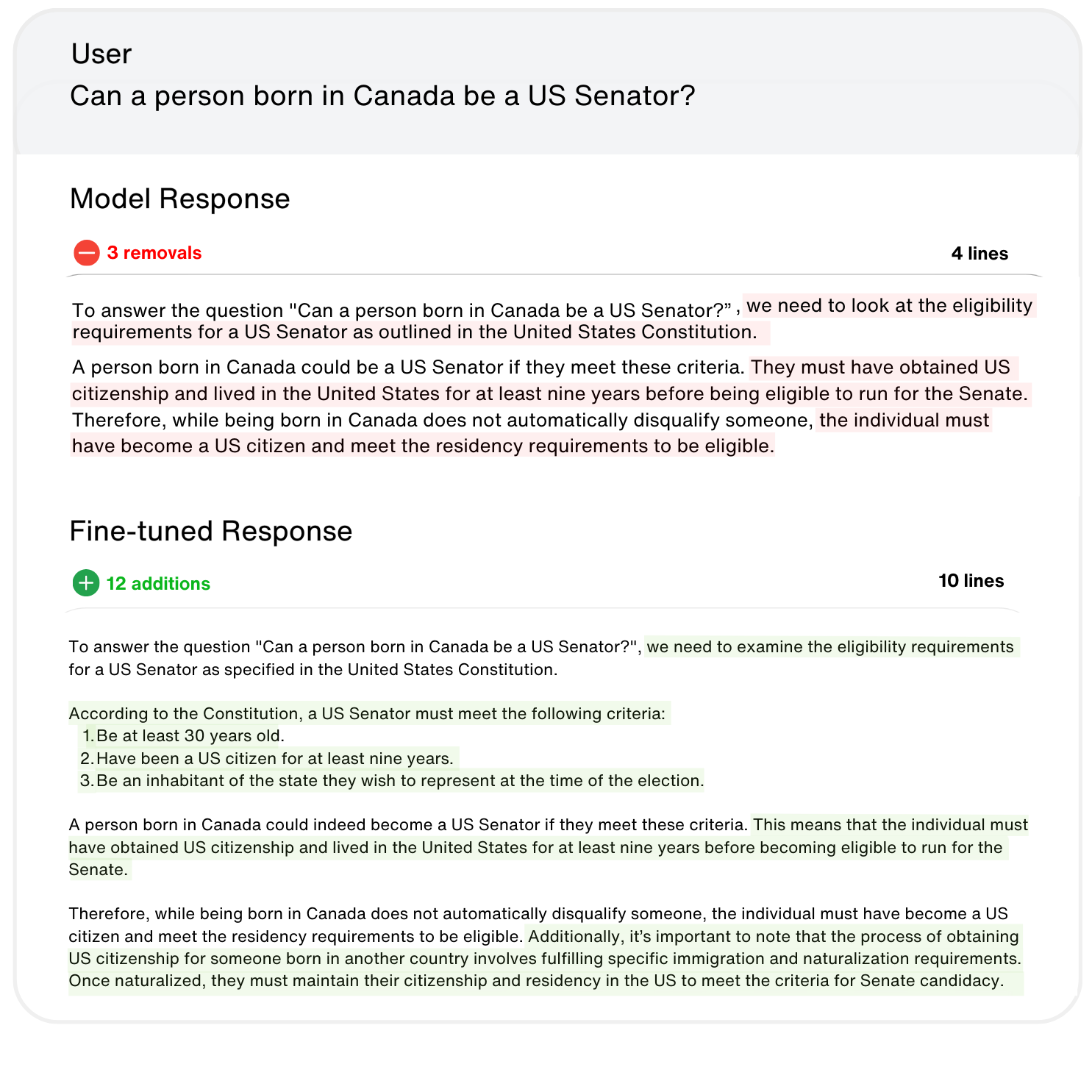
SFT Data
Training from demonstrated desired responses.
Our data, crafted by domain experts, focuses on helpfulness and truthfulness to train large language models. This ensures LLM’s accurate and reliable responses.
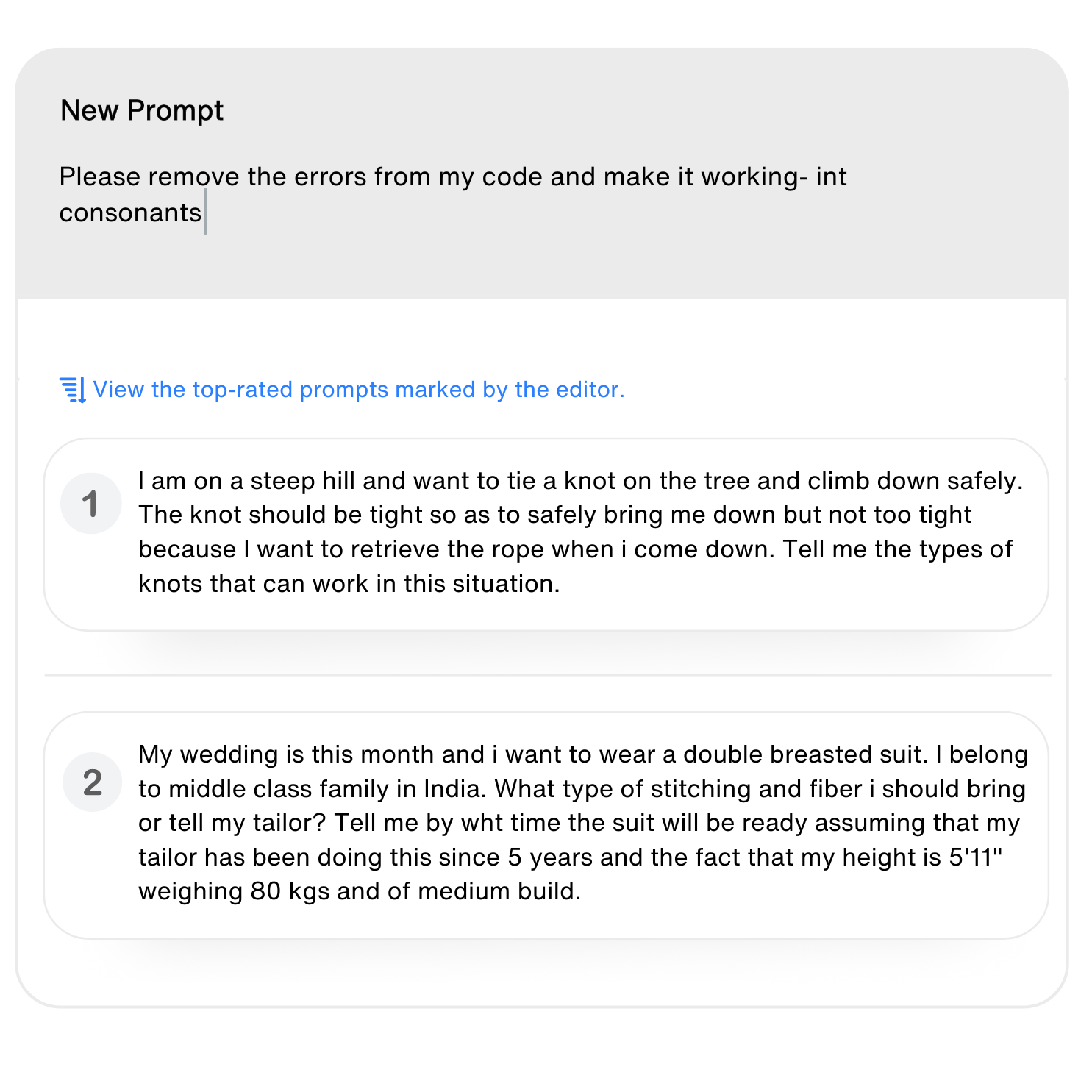
Prompt Creation
Creating natural & diverse prompts to support RLHF
Focusing on real-world scenarios, we ensure AI models are trained for optimal performance and reliability. Prompts are diverse, natural, and tailored for multiple use cases.
WHY US?

Quality
Quality is powered by a team of experts and a robust quality assurance mechanism.

Scale
Process large volumes of data without compromising quality

Ethical Standards
We adhere to strict data privacy regulations and ethical standards.